Architecture
LifeOmic is a software-as-a-service (SaaS) platform hosted on Amazon Web Services (AWS). LifeOmic uses a multi-tenant architecture to offer near-infinite resource capacity when using the platform through the Application Programming Interface APIs.
In multi-tenant architecture, customer data is logically partitioned and segregated by software into the database via a Unique Account Identifier (Unique Identifier) associated with every piece of data.
Access to an account’s data is restricted to permissions granted to users.
Billing and usage tracking is rolled up by account.
This is a standard pattern used by cloud infrastructure and SaaS providers.
LifeOmic is Cloud Native
-
Designed for the cloud using true multi-tenant architecture
-
Auto scaling across multiple data centers in multiple regions around the world
-
LifeOmic services deployed inside private subnets of Virtual Private Cloud (VPC)
-
Adheres to strict security and compliance standards (HIPAA, HITRUST, etc.)
Benefits of Cloud Architecture
-
Infrastructure is tailored to our customer's goals and usage patterns
-
"Shared use" model reduces cost
-
Nearly infinite compute and data capacity via AWS cloud provider
-
Customers can focus on solving business problems and not worry about infrastructure
-
Automatic backup and recovery
-
Continuous improvements via change control process
-
Faster adoption of new technology
-
Increased security due to a secure base platform and best practices
AWS Lambda functions
LifeOmic strives to leverage AWS Lambda functions as the primary building blocks for the following reasons:
-
Functions deploy more quickly than containers and virtual machines.
-
AWS can automatically scale Lambda functions based on the number of incoming invocations and our concurrency settings.
-
Functions are short-lived processes which minimize attack surface.
Advanced Analytics and Machine Learning
- Big data batch jobs via Apache Spark and other tools
- Machine learning
- Run unsupervised and supervised learning models
- Data visualization
- Store output in S3 or indexed datastore
Security and Data Protection
-
Zero-trust security model - Granular segregation and policy enforcements with no "keys to the kingdom" and therefore no single points of compromise.
-
"Air-Gapped" environments meet short-lived processes - Fully isolated sandboxes to prevent accidental or malicious access. No direct administrative or broad network connectivity, such as VPN or SSH access, into production. Processes are short-lived and killed after use. This ensures minimal persistent attack surface and makes it virtually impenetrable.
-
Need-based temporary access - Access to critical systems and resources are closed by default, granted on demand, and protected by strong multi-factor authentication.
-
Immutable builds - Infrastructure as code. Security scan of every build. Full traceability from code commit to production. "Hands-free" deployment ensures each build is free from human error or malicious contamination.
-
End-to-end data protection - Data is safe both at rest and in transit, using strong encryption and key management.
-
Strong yet flexible user access - Our platform supports OpenID Connect, SAML and multi-factor authentication, combined with fine-grain attribute-based authorization.
-
Watch everything, even the watchers - All environments are monitored; all events are logged; all alerts are analyzed; all assets are tracked. Security agents are baked into standard system images and auto-installed on all active systems and endpoints. No privileged access without prior approval or full auditing. We even have redundant solutions to "watch the watchers".
-
Usable security - All employees receive security awareness training not annually, but monthly. Combined with simplicity and usability, we ensure our security policies,processes, and procedures are followed without the need to get around them. No "Shadow IT".
-
Centralized and automated operations - API-driven cloud-native security fabric that centrally monitors security events, automates compliance audits, and orchestrates near real-time risk management and remediation.
-
Regulatory compliant and hacker verified - Fully compliant with HIPAA / HITECH / HITRUST. Verified by white-hat hackers.
Logging, Metrics, and Alerts
- Track everything
- Report alerts
- Developers on-call for high error rates or critical alerts
- Public-facing status page
Usage-based Billing
-
The LifeOmic Platform automatically provisions compute resources based on the job criteria.
-
Pay for what you use
- API calls
- Storage
- Compute resources
Uninterrupted Service
The LifeOmic Platform complies with the Amazon Web Services Well Architected guidelines for high availability, which includes:
-
All server clusters (databases, Elasticsearch, etc...) have at least two instances in an active/active setup spread across at least two availability zones. Each availability zone is a geographically separate data center.
-
Data at rest is stored in high availability AWS services (DynamoDB, S3, Aurora) that store the data redundantly across at least three availability zones, which makes the data itself highly available and durable even in the face of the loss of an entire cluster.
-
A serverless architecture whenever possible that utilizes AWS CloudFront, API Gateway and Lambda to implement a stateless microservice architecture so that the loss of a server or an entire data center is irrelevant. API Gateway and Lambda run on distributed clusters spread across multiple availability zones, and CloudFront runs on a distributed cluster spread across multiple regions.
-
"Design for Failure" - Always plan for failure and provide mechanisms to retry or rollback changes.
-
Rolling updates to services for zero downtime.
-
Load balancing and health checks to automatically remove unhealthy actors from the platform and repair.
Account (organization) and User Entity Relationship Diagram
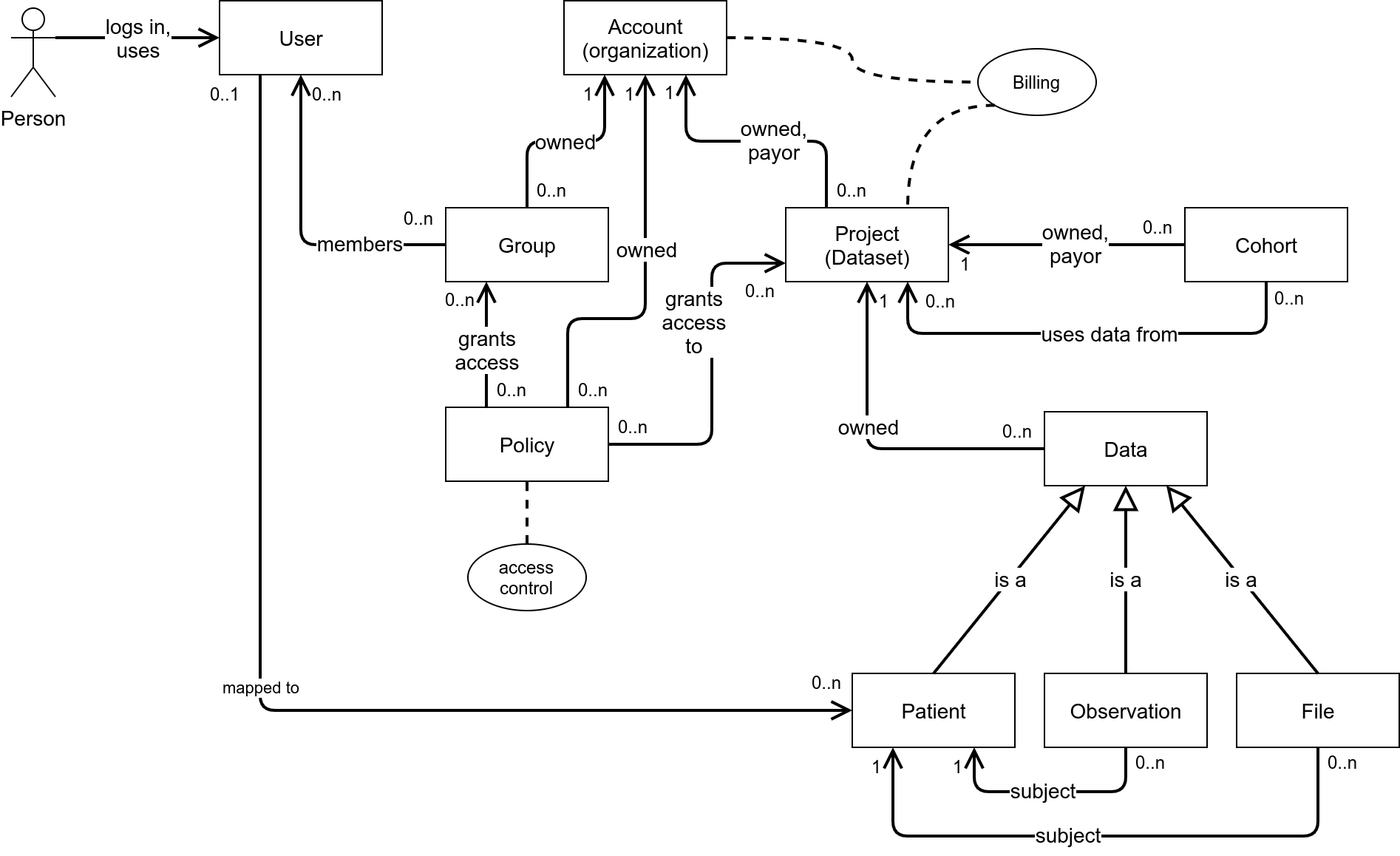
Terms
-
Person - A Person is a human being who uses the platform (such as a researcher, clinician, administrator, or patient).
-
User - Users represent people who are using the platform and provide authentication, demographic, and contact information. Users are not owned by accounts, and a single user may have access to multiple accounts via group membership.
-
Account - An account is the top level organizational structure for the platform. Typically each organization would have a single account. Accounts store the billing/payment method for an organization and are used by the platform to bill for usage.
-
Group - Groups live inside an account and are the primary mechanism of binding a user to an account and giving the user access to data in the account.
-
Policy - ABAC (Attribute Based Access Control) policies control what groups have access to what projects in an account. Policies live inside an account.
-
Project - Projects form an organizational structure under an account and also provide a finer grained breakdown of usage for internal accounting inside an organization. Projects are the typical granularity for access control. Projects are also used to aggregate storage costs up to an account. In our APIs, "dataset" is synonymous for "project".
-
Cohort - Cohorts are basically a saved search. They provide a way to pull in data from multiple projects and subsets of projects. Typically, cohorts do not result in data copies or extra storage costs (except for ephemeral data used for analysis).
-
Data - Data are all the various pieces of data about patients that are stored in the platform. Data can be just about anything. Some examples: Patient, Observation, Condition, Procedure, Medication, Image, ClinicalReport, BAM File, VCF File, and others. Data is stored inside a project within an account.
-
Patient - A Patient resource is a type of data that stores the demographic information for a Person as a research subject, patient, customer or employee in a project within an account.
User and Patient Mapping
The LifeOmic Platform has two representations of people:
- Users - these are people who can log into the LifeOmic Platform app and interact with it: employees, partners, or customers/subjects/patients.
- Patients (aka Subjects) - these are people whose health data is tracked by the LifeOmic Platform. A Patient resource does not, by itself, give a person any access to the LifeOmic Platform.
A User can be mapped to a Patient (via an invitation, see below) so that you can have a person who both signs into the LifeOmic Platform and has their health data stored in the LifeOmic Platform. When a User is mapped to a Patient, this grants the User access to the data for the Patient via an ABAC policy associated with the Subjects group. The Subject Access policy and Subjects group are created automatically by the LifeOmic Platform. When a User is mapped to a Patient, the User record also provides a way to send notifications with an email to the email address on the User record or a push notification to the patient engagement mobile application.
User records are created automatically when someone signs up for the LifeOmic Platform and can be associated with an account via an invitation. The two types of invitations are:
- Account Invitation - This simply adds a User to a Group when the person accepts the invitation. The User has whatever access is granted to the group via an ABAC policy.
- Project Invitation - This works like an Account Invitation but also maps the User record to a Patient record in a particular Project. The group for Project Invitations is always the Subjects group.
For both types of invitations, the person being invited receives an email directing them to signup or login and accept the invitation. See Groups for a step-by-step guide to inviting users.